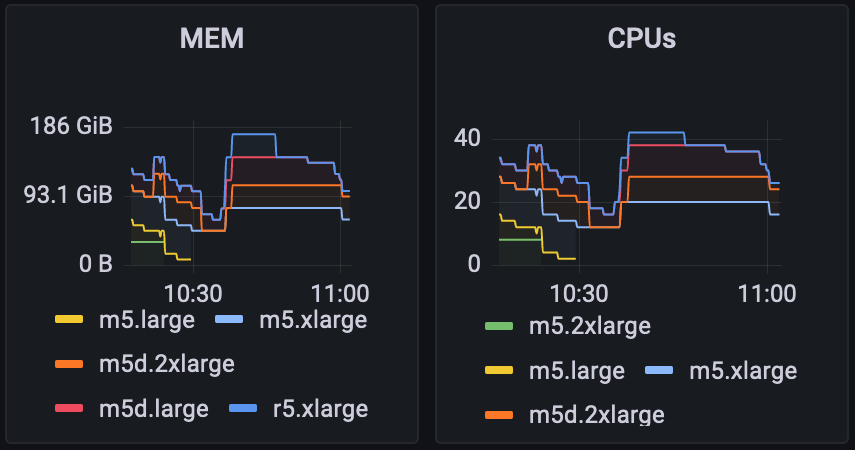
DaP gallery
snippets of DaP interfaces
- monitor the Beacon Chain initial sync in Grafana
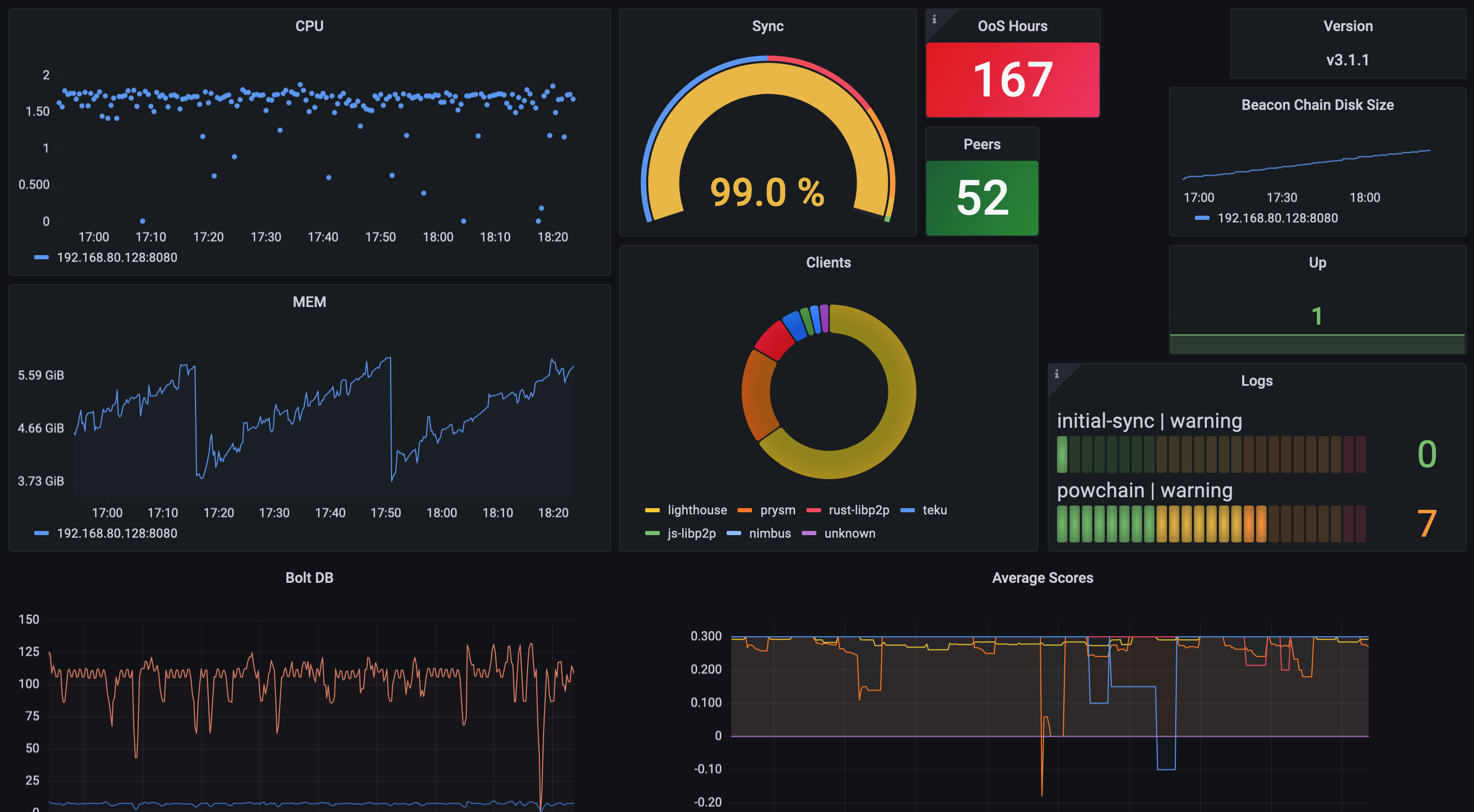
- extract smart contract events from a The Graph manifest ( subgraph.yaml ) in 2 lines of code
from dap.events.dag import dapp
airflow_dag = dapp('uniswap', 'uni', schedule_interval='40 1 * * *', thread_deciCPU=9)()
- the resulting Airflow dag is managing tasks according to the blockchain node capacity

No other job is hitting the Ethereum client currently running on 8 vCPUs. Accordingly, 7 tasks are active (5 running and 2 ready to start in the queue). This leaves 1 full vCPU dedicated to Geth.
- the connection pool reveals seconds later that the 2 tasks previously in the queue started

They are 10 slots per allocatable CPU, i.e. 1 slot = 1 deciCPU = one tenth CPU. 7 Web3 requests times 9 thread_deciCPU (code snippet above) add up to 63. No other block search task can be queued.
- resources are well tuned for this job because they maximized the allocatable bottleneck (CPU)
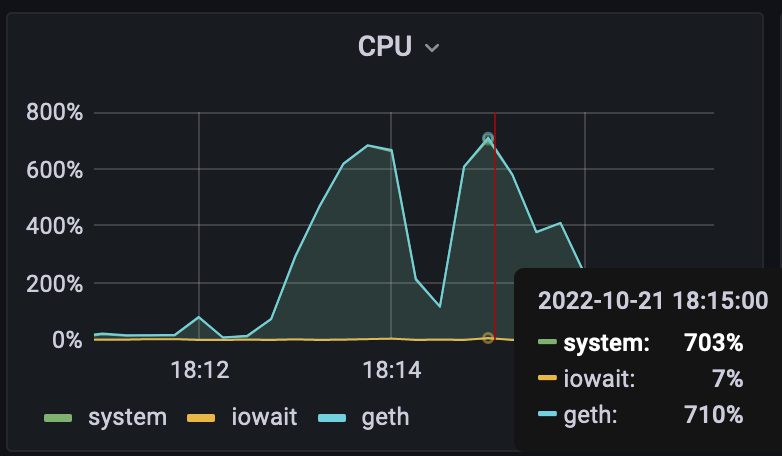
The 30s drop occurred when most tasks completed in the first batch, before the scheduler kicked in.
- focus on business logic when leaving data sync and block reorg to DaP checkpoint modules
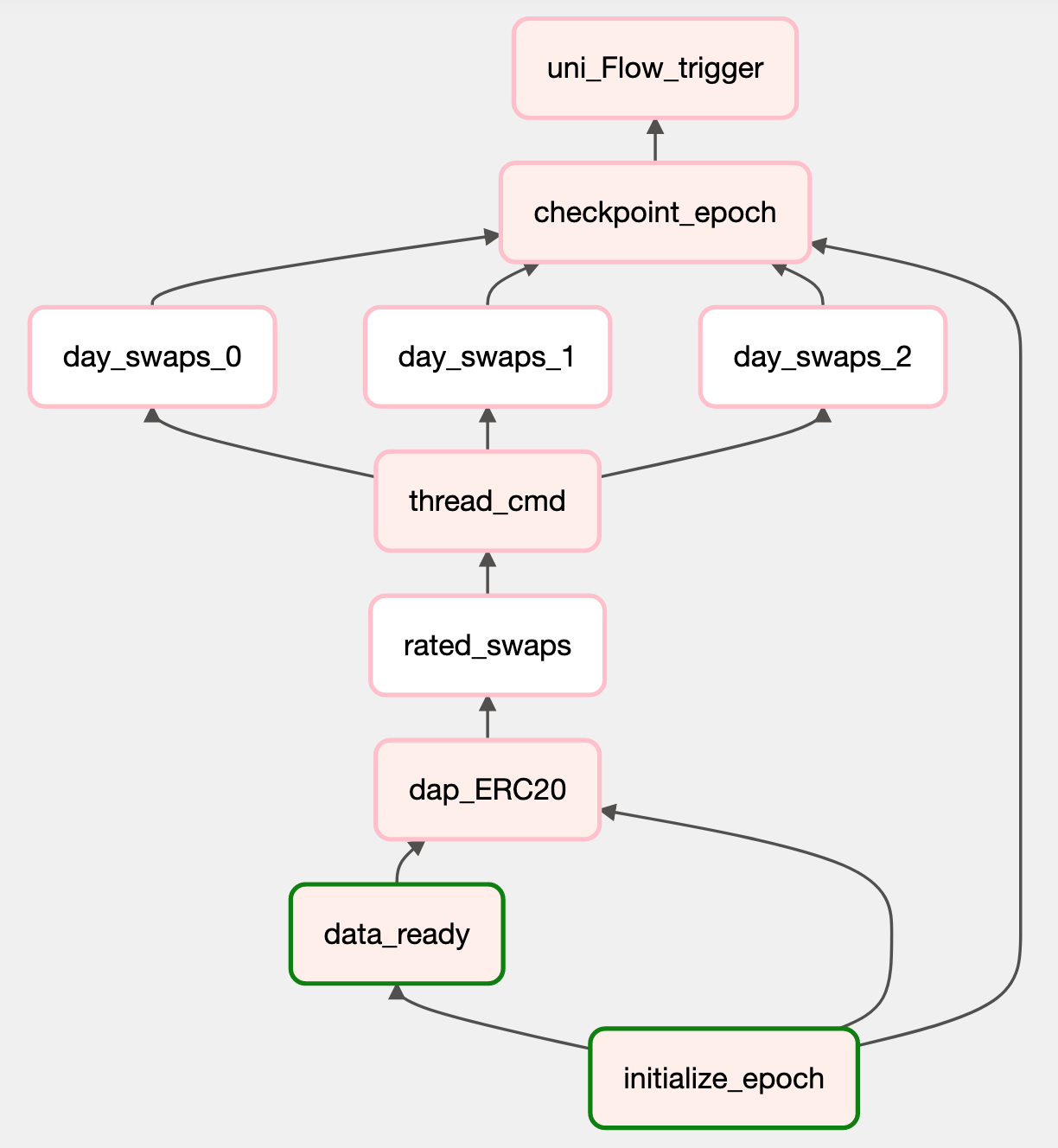
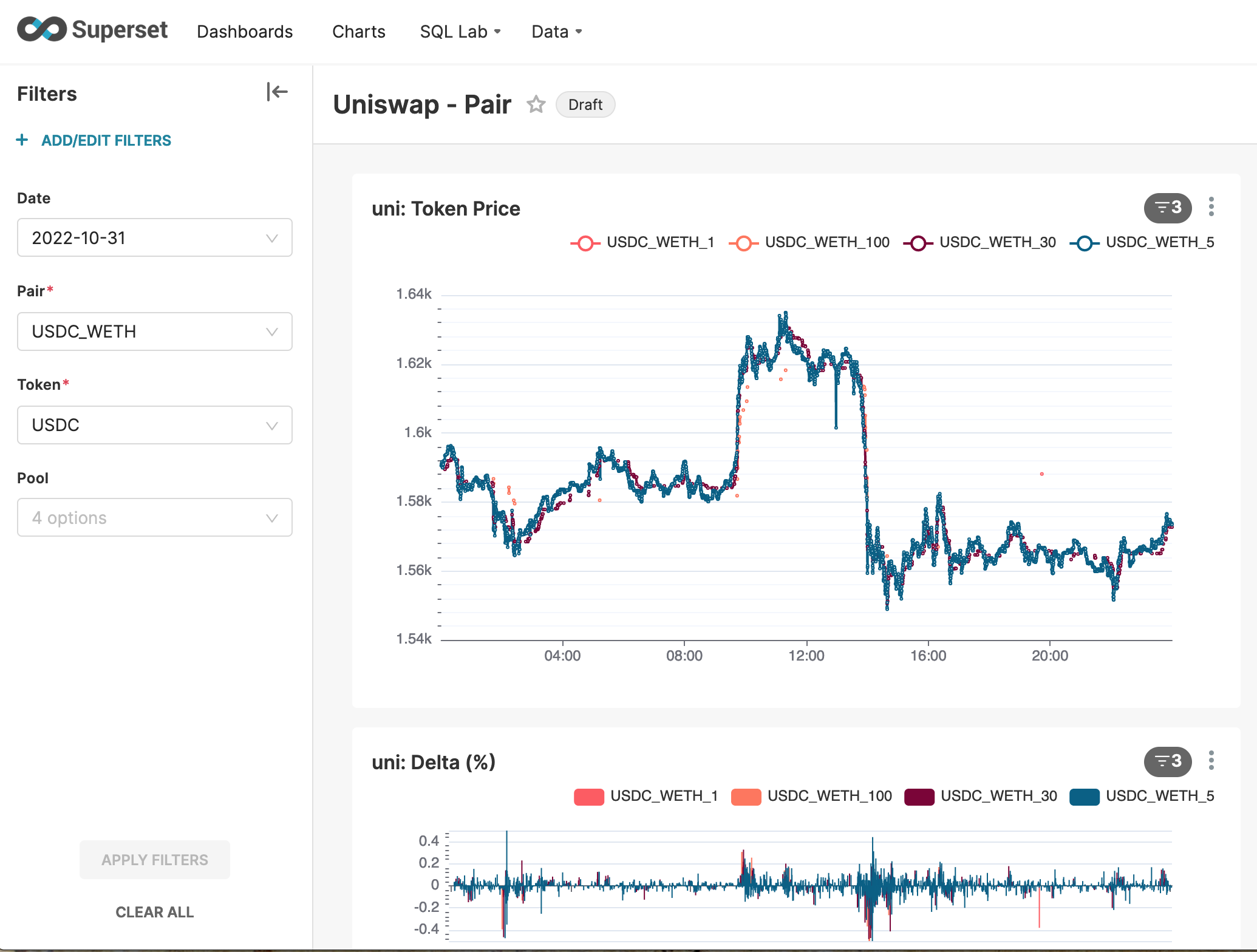
- visualize data in Superset and create dashboards
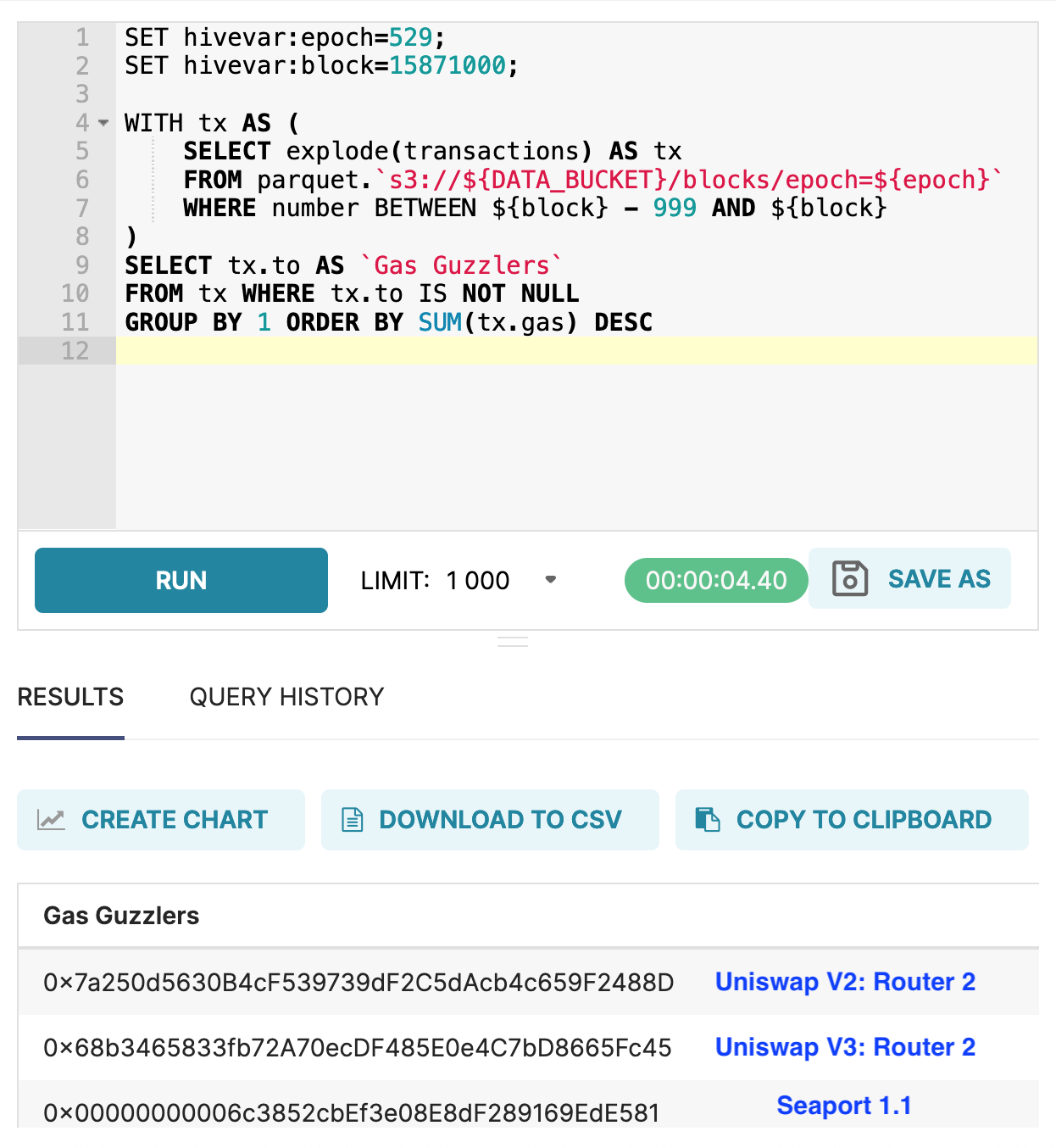
- query block data in SQL Lab to return top Gas Guzzlers like Etherscan
- the token & fee pricing algorithm explained by the throughput of pods in Spark namespace
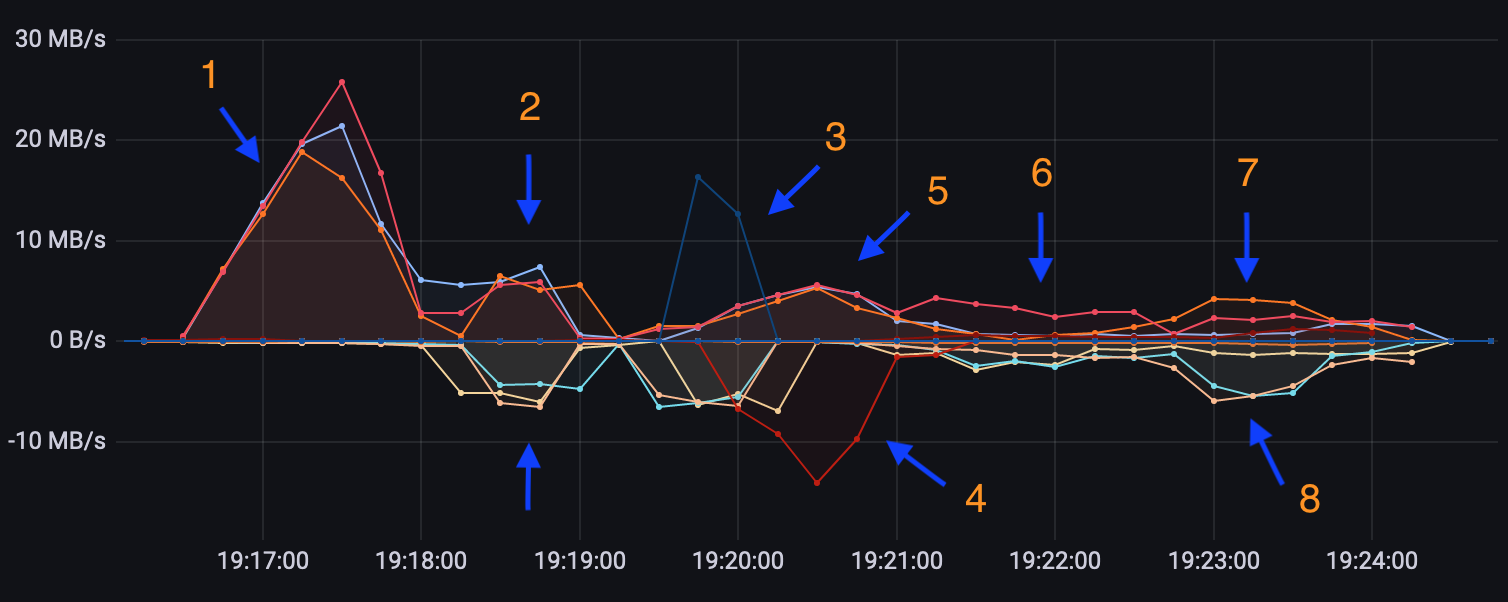
- high batch throughput of 3 Spark executors ingesting 40k blocks and Uniswap events
- executors shuffle data between them to join block transactions with token swaps
- output of batch process is ordered into a Kafka buffer (one-node cluster) tied to the app
- egress of Kafka topic simulating a live data feed peaks a minutes after the ingress
- executors calculate independent metrics like price change in even streams partitioned by pool
- all data streamed to pink executor, synchronizing transactions with the latest Ethereum quote
- while the pink is still busy, data streams to the orange executor to apply the live USD quote
- "rated" swaps on live price quotes are persisted into the data lake
If your definition of accuracy is as raw as it gets and includes real price distortions, this is it.
- no need to manage the complex system layer, Argo CD reconciles and builds unattended
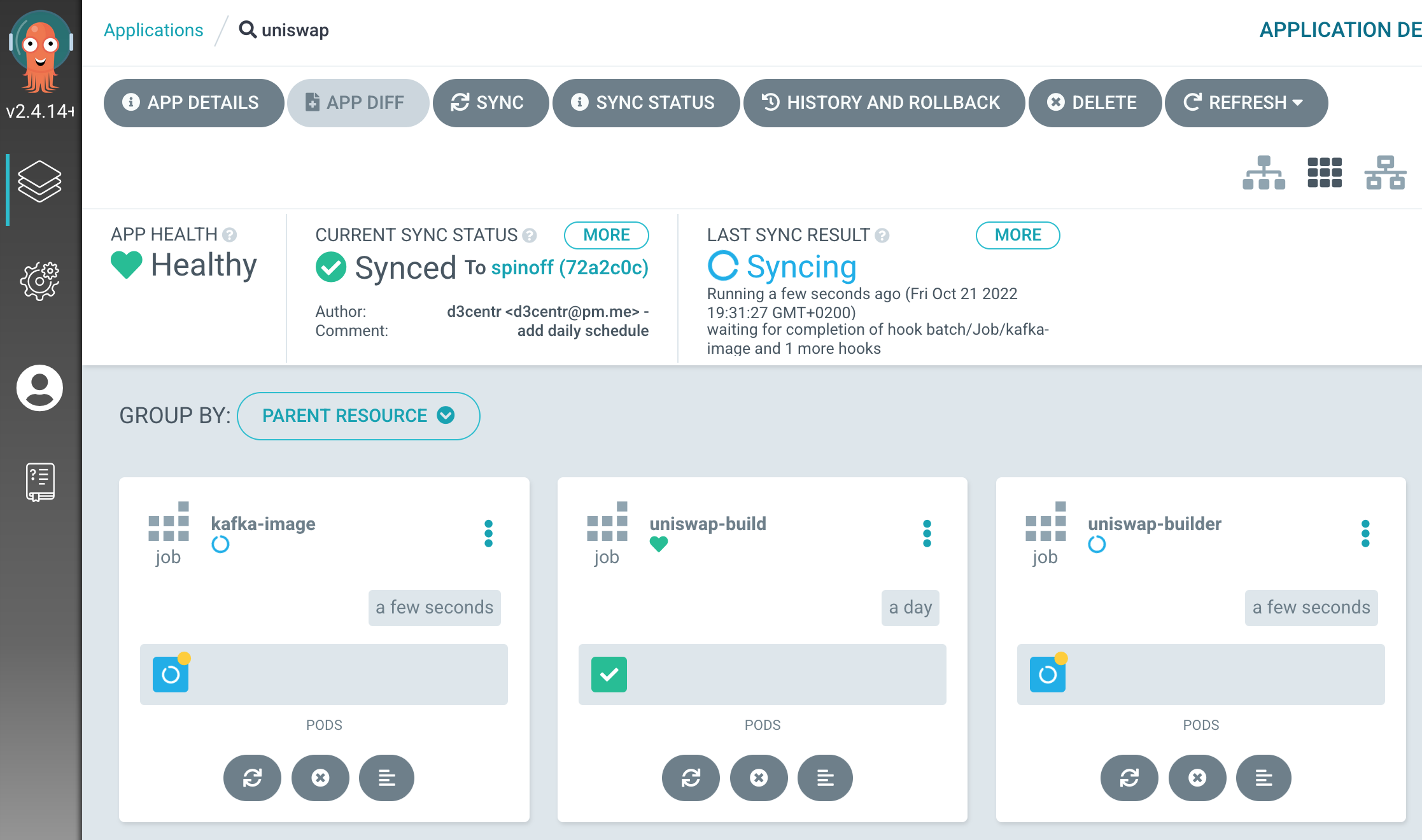
- no boilerplate, adding internal charts to a Spark app will build and run it
Helm Chart.yaml
apiVersion: v2
name: uniswap
version: 0.1.0
dependencies:
# add build profiles and spark distribution versions
- name: profile
version: 0.1.0
repository: "@spark"
import-values:
- all
# actual build jobs parameterized by profile chart
- name: build
version: 0.1.0
repository: "@spark"
# provision a kafka buffer tied to the app
- name: buffer
version: 0.1.0
repository: "@spark"
- K8s autoscaler can double cluster size within 2m, scaling down progressively with workload